
C’est en numérisant des journaux historiques au début des années 1990 que la technologie OCR est devenue populaire. Depuis lors, cette technologie a considérablement évolué. Les solutions actuelles sont capables de fournir une précision d’OCR quasi parfaite.
Les flux de travail complexes de traitement des documents sont automatisés à l’aide de méthodes avancées. Avant l’arrivée de la technologie OCR, la seule façon de mettre en forme des documents numériques était de retaper manuellement le texte. Cela prenait non seulement beaucoup de temps, mais comportait également des inexactitudes et des erreurs de frappe.
Actuellement, les services d’OCR sont désormais largement accessibles au grand public. Google Cloud Vision OCR, par exemple, est utilisé pour numériser et stocker des documents sur votre smartphone.
Qu’est-ce que l’OCR ?
En utilisant des capacités automatisées d’extraction et de stockage de données, la technologie de reconnaissance optique de caractères (OCR) est un processus commercial efficace qui permet de gagner du temps, de l’argent et d’autres ressources.
La reconnaissance de texte est un autre terme pour la reconnaissance optique de caractères (OCR). En effet, les logiciels d’OCR extraient et réaffectent les données de documents numérisés, d’images d’appareils photo et de fichiers PDF contenant uniquement des images.
Le logiciel OCR extrait les lettres des images, les convertit en mots, puis en phrases, ce qui permet d’accéder au contenu d’origine et de le modifier. Il élimine également la nécessité de saisir les données à la main.
De plus, les systèmes de reconnaissance optique de caractères convertissent des documents physiques imprimés en texte lisible par une machine en utilisant une combinaison de matériel et de logiciel. Le texte est généralement copié ou lu par le matériel, tel qu’un lecteur optique ou une carte de circuit spécialisée, puis le traitement avancé est assuré par le logiciel.
Les logiciels d’OCR peuvent utiliser l’intelligence artificielle (IA) pour mettre en œuvre des méthodes plus avancées de reconnaissance intelligente des caractères (ICR), telles que l’identification des langues ou des styles d’écriture. Aussi, l’OCR est le plus souvent utilisée pour convertir des documents juridiques ou historiques sur papier en documents PDF. Ainsi, les utilisateurs peuvent modifier PDF, formater et rechercher comme s’ils avaient été créés avec un traitement de texte.
Comment convertir un PDF scanné en PDF modifiable avec PDFelement ?
Voici un guide de 3 étapes qui vous permettra de convertir un PDF scanné en PDF modifiable, de manière très simple, grâce à PDFelement :
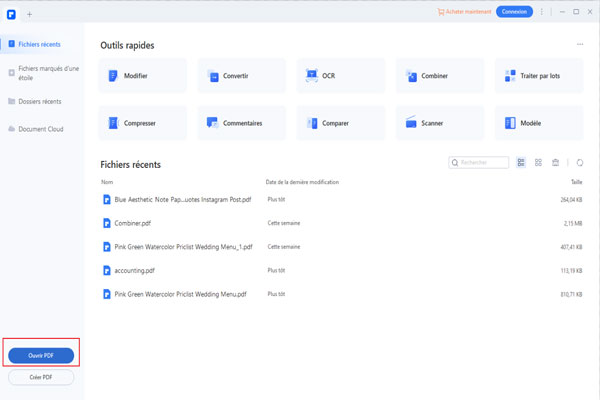
1- Naviguez vers le PDFelement numérisé.
Lancez PDFelement et ajoutez votre fichier en cliquant sur le bouton « Ouvrir des fichiers » sur la page d’accueil.
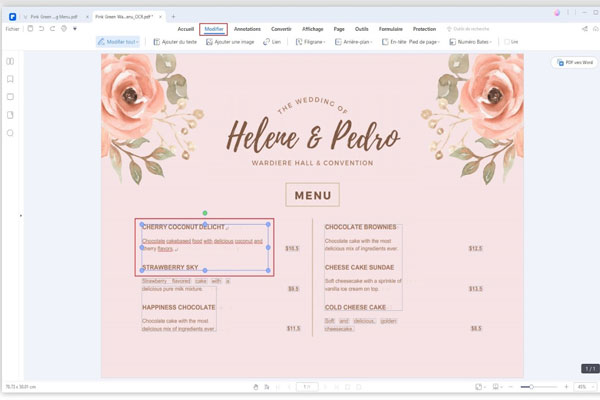
2- Sur le document numérisé, effectuez l’OCR.
Un message pop-up vous invite à effectuer une OCR sur le fichier PDF numérisé. Appuyez donc sur le bouton « Exécuter l’OCR ».
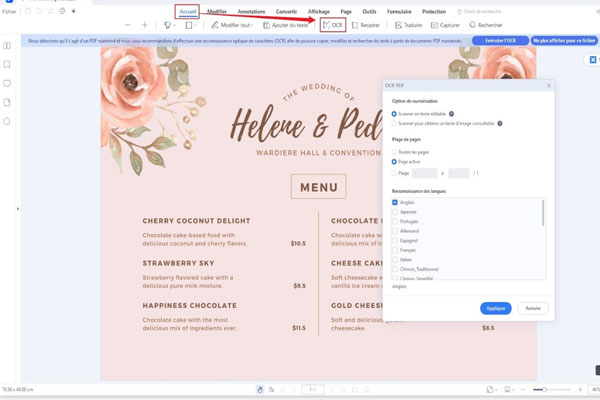
3- Apportez des modifications à un fichier PDF numérisé.
Une fois l’OCR terminée, vous pouvez apporter des modifications au fichier PDF. Pour commencer, allez dans l’onglet « Editer ».
Que peut faire PDFelement pour l’OCR PDF ?
PDFelement dispose de plusieurs fonctionnalités, notamment au niveau de l’OCR PDF. Ces dernières sont énumérées ci-dessous :
– Modifier le texte du document PDF numérisé :
Les documents PDF numérisés sont parmi les plus difficiles à traiter. Lorsque vous numérisez un document et que vous l’enregistrez au format PDF, l’ensemble du texte, des graphiques et des images est fusionné en un seul gros fichier image qui ne peut pas être modifié. Pour faciliter la manipulation d’un document numérisé, déstructurez la grande image en éléments gérables dans le document.
– Convertir l’image au format Microsoft Office modifiable.
Lorsqu’un document est numérisé, il est généralement enregistré sous la forme d’un fichier image qui peut être visualisé dans un éditeur d’images ou en tant que PDF. Ces images peuvent contenir du texte, mais celui-ci ne peut pas être modifié à l’aide de traitements de texte standard tels que Microsoft Word. La reconnaissance optique de caractères (ROC) est une technologie révolutionnaire qui permet de numériser des documents et de convertir tout texte contenu dans l’image en texte modifiable. L’utilisateur peut ainsi ajouter, modifier et supprimer du texte à partir de numérisations d’images qui n’étaient pas éditables auparavant.
– Extraire les données du PDF scanné.
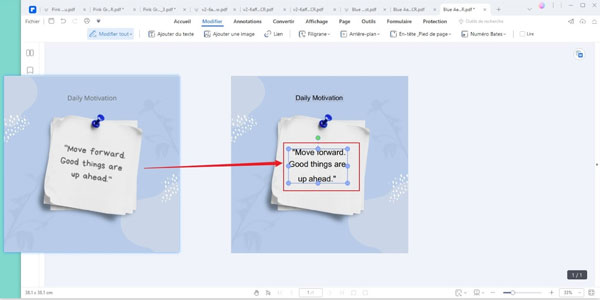
Vous pouvez réorganiser efficacement les données de votre ordinateur en les extrayant d’un PDF.
Conversion par lots de fichiers numérisés en fichiers modifiables
Voici un guide de traitement par lots de l’OCR avec Wondershare PDFelement :
1- Sélectionnez » Traitement par lots » dans le menu
Pour commencer, lancez l’application sur votre ordinateur. L’écran d’accueil de l’application s’affiche. Passez à l’étape suivante en sélectionnant « Traitement par lots ».
2- Ajoutez plusieurs fichiers numérisés
Lorsque l’écran de traitement par lots apparaît, sélectionnez « OCR », puis « Choisir fichier ». Sélectionnez autant de fichiers PDF que vous le pouvez et faites-les glisser dans le programme. Il est plus facile de télécharger les fichiers PDF en une seule fois si vous les organisez dans un dossier.
3- Choisissez une langue d’OCR par lots
Une fois que vous avez téléchargé les fichiers PDF dans le programme, vous devez sélectionner la langue à utiliser pour l’OCR. Ceci est généralement déterminé par la langue des documents. Naviguez vers la droite et sélectionnez l’option OCR, puis sélectionnez la langue de votre choix.
4- Configurez le dossier de sortie pour l’OCR par lots
L’étape suivante consiste à spécifier le dossier de sortie des fichiers d’OCR par lots. L’option de sortie est située juste en dessous de l’option de langue de l’OCR.
Après cela, cliquez sur « Appliquer » pour l’OCR par lots des fichiers PDF.
5- Terminez le processus d’OCR par lots
Le logiciel d’OCR par lot va commencer le processus immédiatement, et la progression sera affichée à l’écran. Il ouvrira automatiquement le dossier de destination pour vous une fois que tous les PDF que vous avez téléchargés auront été traités avec succès.
6- Après avoir effectué l’OCR, éditez le fichier PDF.
Vos documents PDF sont maintenant modifiables et consultables. Naviguez jusqu’au dossier où vous avez enregistré les fichiers OCR par lots et ouvrez les fichiers avec PDFelement.
Ensuite, dans le menu principal, sélectionnez « Édition », puis le bouton d’édition pour sélectionner les options d’édition en mode ligne ou en mode paragraphe. Ensuite, naviguez jusqu’au paragraphe que vous souhaitez modifier et cliquez dessus. Vous pouvez facilement supprimer du texte, ajouter du nouveau texte, des liens et des images en utilisant le retour arrière.
Conclusion
La simple création de modèles de documents ne suffit plus, car les entreprises veulent également des informations. La méthode de l’OCR s’avère être une stratégie gagnante pour la capture de données, car les logiciels de reconnaissance collectent des informations tout en comprenant le contenu.
Wondershare PDFelement peut vous aider à faire passer votre automatisation au niveau supérieur, grâce à ses fonctionnalités, qui sont destinées à améliorer votre manipulation des fichiers PDF.
Donnez votre avis